Last Wednesday we were given a talk by Ben, one of the third years at Queens’. His talk introduced us to some very recent popular computer science topics and a way to combine them under his Part II project “Parallelized Deep Learning for Convolutional Neural Networks on the Intel Xeon Phi”.
He started his talk by explaining how neural networks work. We’ve seen how they aim to process information in a way similar to how biological systems, such as the brain, do it. Their structure gives the impression of a brain, by having multiple interconnected layers, each of them composed of multiple neurons. Neurons are just processing units that apply a predefined function to a set of inputs. Convolutional Neural Network are a particular case in which the function applied in each neuron is a convolution. The following picture represents the structure of a neural network, and it shows how one neuron applies its function.
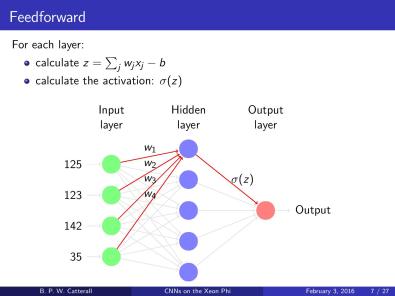
Ben then explains that you can train such networks to make different “intelligent” decisions – his example was understanding handwritten digits. The training can be done by minimizing the error for each training sample – in a way similar to letting a ball roll down a hill.


The theory behind all of this is as old as 1980, but requires quite high computational power. Due to recent advances in technology, using such a structure has become a feasible thing. For his project, Ben uses the Intel Xeon Phi co-processor, specialized to do parallelized computing. By splitting and parallelizing the calculation, Ben showed us how you can reduce the training time to mere seconds, compared to several days.
