Dhruv’s part II project is titled “Interpolation in the Latent Space of Variational Autoencoders”. None of us had any idea what that means, so this week Dhruv aimed to help us all to understand that that means, why it’s useful, and how it’s done, with the promise that it would try to add some science to the black box of machine learning.
The first step was to explain what a variational autoencoder is. The basic idea behind them is that they take an image in a particular domain, or some other data, and convert it to a few numbers (in this project, they were converted to 2 numbers), from which the image can be approximately reconstructed later. The values were also weighted to follow a normal distribution, which, taken with the limited number of values per image, should mean that the values represent something useful about the image. The aim is to let us interpolate between the values from two images to get an interpolation that makes sense, such as interpolating between slanted “1”s to get a straight “1”.

Interpolation between two slanted ones gives a straight one
The first dataset used to test the model is a set of hand-written numbers. The values chosen for each of the images are tightly clustered by the number in the image, which means that the model is working well; when interpolating between images of the same number, it usually looks natural. However, there are a few points where different numbers are overlapping, which results in the model giving distorted combinations of the numbers when asked to interpolate across this region.
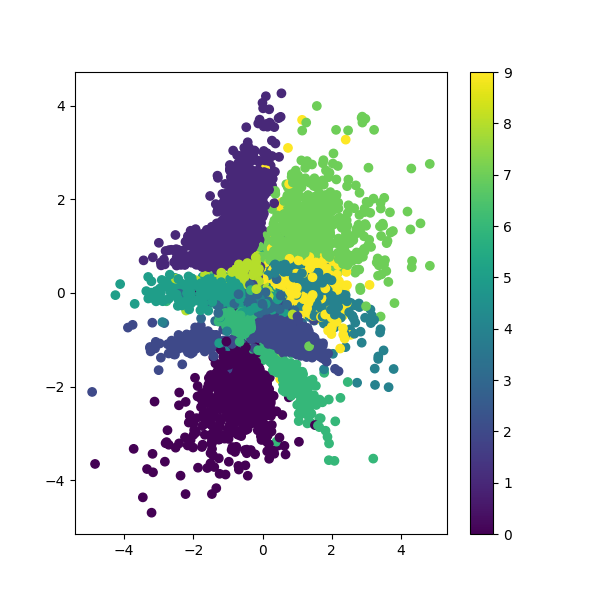
Plotting hand drawn numbers in the 2D latent space. Most of the numbers are clustered well, but there is some overlap between 5 and 3 in the centre of the plot.
The second dataset is a collection of photos of objects taken from several different angles, to try and interpolate between the angles and produce an image from a different perspective. Dhruv is still working on refining the model for this dataset, but currently it produces quite blurry images.

You must be logged in to post a comment.